Display the result
Each pixel has now an image assigned, now we need a way to display the whole image.
Challenges with large pictures
In the last step we created an 2D-array of filenames where the position in the array, corresponds to the position of the pixel for the image should be used.
We could now just “paste” the images together and call it a day. BUT… there is a small problem… We are going to replace each pixel of a 1080x1080 picture with 1920x1080 pictures. The resulting resolution would be (1920*1080)x(1080*1080) = 2073600 x 1166400, which are freaking 2.42 tera pixels. Trying to save this would result in a 7.26 TB BMP or a 494 GB JPEG at full quality. Try to find a computer and viewer that is able to display this…
Trying to print it at 600 dpi would require 87.78m by 49.38m, 4334m² (288.0ft by 162.0ft, 46656 sq ft), more than half the size of a standard football field (soccer, not American football). Costing around €35000 (~ US$ 41000) to print… So rather a large problem.
So as displaying it would light computers on fire and printing it would empty the bank account, we need a better way to display it. And it is called a tiled image pyramid and a tiling image viewer only loading the required parts. This works essentially in the same way as your OpenStreetMap or Google Maps. You have a low resolution overview image getting more detailed the more you zoom in.
Building an image pyramid
To use this technique, we first need to generate the image pyramid. Which are just layers of the image with decreasing resolution, split into equally sized tiles. I choose to cut, with each layer, the horizontal and vertical resolution in half, resulting in each layer being quarter of the size of the previous one. The deepest layer are just each individual picture at their full 1920x1080 resolution, decreasing on the way up.
| Layer | Image resolution | Tile resolution | Images per tile | Number of tiles* |
|---|---|---|---|---|
| 8 | 1920x1080 | 1920x1080 | 1x1 = 20x20 = 40 = 1 | 1080x1080 = 1166400 |
| 7 | 960x540 | 1920x1080 | 2x2 = 21x21 = 41 = 4 | 540x540 = 291600 |
| 6 | 480x270 | 1920x1080 | 4x4 = 22x22 = 42 = 16 | 270x270 = 72900 |
| 5 | 240x135 | 1920x1080 | 8x8 = 23x23 = 43 = 64 | 135x135 = 18225 |
| 4 | 120x67.5 (120x68) | 1920x1080 | 16x16 = 24x24 = 44 = 256 | 68x68 = 4624 |
| 3 | 60x33.75 (60x34) | 1920x1080 | 32x32 = 25x25 = 45 = 1024 | 34x34 = 1156 |
| 2 | 30x16.875 (30x17) | 1920x1080 | 64x64 = 26x26 = 46 = 4096 | 17x17 = 289 |
| 1 | 15x8.4375 (15x9) | 1920x1080 | 128x128 = 27x27 = 47 = 16384 | 9x9 = 81 |
* for a 1080x1080 picture
Building the tiles could be done recursively (one of the few cases where it would benefit the performance). Either top-down or bottom up, always placing 4 tiles of the larger layer into 1 tile of the smaller one. This would be very fast, efficient and easy to program. But it would sacrifice visual quality, because the images would start to blend into each other while resizing them.
To prevent this all layer would need to build from ground up. Resizing each picture for the tile, pasting it to the correct coordinates. This is slow and hard to code, but it’ll keep more or less sharp edges between pictures.
To do that we need to iterate over the coordinates of the tile in the meta-image and the coordinates of the image inside the tile. The tile column-major Cartesian coordinate would be $ (j,i) $ and $ (l,k) $ for the image inside the tile. From two coordinates we then need to calculate the global $ (x,y) $ coordinate for the file.
That’s why it is important to know the difference between row-major and column-major indexing and when and where they are used.

The global index is the index of the tiles first image plus the offset $ (l,k) $ in the tile. And the tiles first image index is the number of vertical or horizontal tiles $ 2^h $ in the layer times the tile coordinate $ (j,i) $.
With that in mind it just a matter of resizing and pasting the images on the tile and upload the tile to its final destination.
Generate the tiles with python
With the math out of the way, generating the tiles is quite straight forward.
for h in range(8):
ratio = pow(4, h) # zoom is 1:ratio
cols_rows = pow(2, h) # cols_rows x cols_rows on one canvas
level = 8 - h
print("LEVEL RATIO 1:{}".format(ratio))
startlevel = datetime.now()
for i in range(1,int(ceil(new_img_fns.shape[0] / cols_rows))):
startrow = datetime.now()
for j in range(int(ceil(new_img_fns.shape[1] / cols_rows))):
startcol = datetime.now()
# canvas cell
loc_n = "{}/{}/{}/{}.jpg".format(name_base, level, i, j)
img_width = int(ceil(1920/cols_rows))
img_height = int(ceil(1080/cols_rows))
base_canvas = Image.new("RGB", (1920, 1080))
z = 0
for k in range(cols_rows):
for l in range(cols_rows):
z += 1
try:
img_fn = new_img_fns[i * cols_rows + k, j * cols_rows + l]
except IndexError:
img = Image.new("RGB", (1920, 1080))
img_d = ImageDraw.Draw(img)
img_d.rectangle(((0, 0), (1920, 1080)), fill="black")
else:
print(z, end='\r')
img_path = os.path.join(frames_data, img_fn[:-len("_000000.jpg")])
img = Image.open(os.path.join(img_path, img_fn))
if img.size[0]/float(img.size[1]) > 16.0/9.0:
new_width = int(ceil(img.size[1] * 16/float(9)))
offset = int(ceil((img.size[0] - new_width)/2.0))
img = img.crop((offset, 0, new_width, img.size[1]))
# resize to level size
img = img.resize((img_width, img_height), resample=Image.BICUBIC)
base_canvas.paste(img, (img_width*l, img_height*k))
pre = random.randint(10000, 99999)
tn = os.path.join("/dev/shm", "{}{}".format(pre, loc_n.replace("/", "")))
base_canvas.save(tn)
print(b2_bucket.upload_local_file(local_file=tn, file_name=loc_n))
os.unlink(tn)
print("COLUMN: {}".format(datetime.now()-startcol))
print("ROW: {}".format(datetime.now()-startrow))
print("LEVEL: {}".format(datetime.now()-startlevel))
We iterate over the number of layers, the number of tiles vertically and horizontally and the number of images in that tile. Then we double check the correct aspect ratio of the image, cropping it if necessary, resize it and paste it on the canvas.
Last but not least it is uploaded to the desired cloud storage.
Serving the tiles
As the size of the whole pyramid totals somewhere in the neighborhood of 500GB with over 1.5 million files, this is nothing that could be served from a standard webspace or from home.
No, some fancy cloud infrastructure is required. First, we need a cloud space, that allows us to access the files by name, rather than a cryptic ID. This eliminates all the consumer cloud storage options like Google Drive, One Drive and Dropbox. They also don’t like to be abused as webspace, anyways, just blocking the request at some point. So we need a cloud space, meant to be used this way, like Azure Blob storage, Google Cloud Storage, Amazon S3 or Backblaze B2. I decided to use Backblaze because it is the cheapest in terms of $/GB.
But even tho storage is cheap, download bandwidth isn’t. And you will never know how many people are going to view the image. Caching in some form or another is required. A good place to start is the free-tier from Cloudflare. They’ll reduce bandwidth used at the backend while also speeding up global page-load times. But I’ve even gone a step further placed a second cache in between Cloudflare and the storage backend. This will reduce the required bandwidth even more and adds some flexibility that you otherwise would not have with Cloudflares free-tier. This second cache is just a cheap cloud server running a nginx reverse-proxy.
So the whole Architecture would look like this.
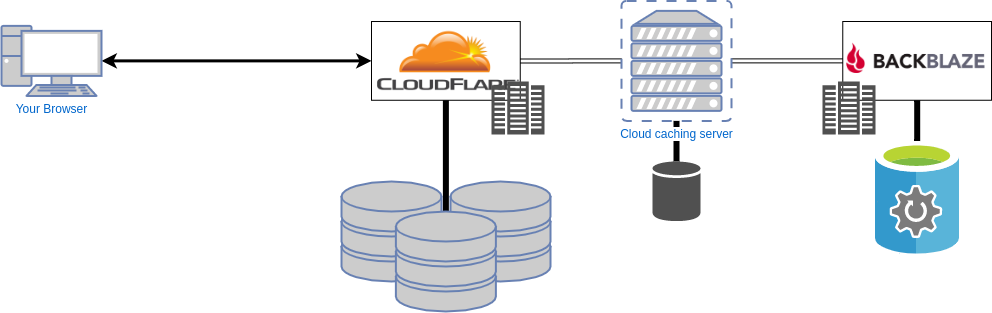
Server setup
Backblaze part
There is not much to set up here. Backblaze manages files (like most of these services) in buckets. As these services are usually use object storage, a bucket can only contain files. There are no folders in an object store. BUT, filenames can contain slashes, behaving like folders when displayed and accessed.
So we just need to create and publically accessible bucket, where we upload the files to. And we need to create application keys to access it. Uploading can be done and is done in the python code, using the SDK provided by Backblaze.
import b2sdk.v1 as b2
info = b2.InMemoryAccountInfo()
b2_api = b2.B2Api(info)
application_key_id = '0000000000000000000000000'
application_key = 'rathecai7ooJ0oogh2eet1oitoo2deiY'
b2_api.authorize_account("production", application_key_id, application_key)
b2_bucket = b2_api.get_bucket_by_name("REDACTED")
Files tan are accessible by their name like
https://f003.backblazeb2.com/file/BUCKETNAME/file/name/with/slashes/that/are/like/folders/but/are/not.jpg
https://BUCKETNAME.s3.eu-central-003.backblazeb2.com/file/name/with/slashes/that/are/like/folders/but/are/not.jpg
Cloudflare part
Even less to set up here. Just sign up, set the nameservers for your domain (yes, you need an own domain for this) and set up the IPs for the Webspace and cache server.
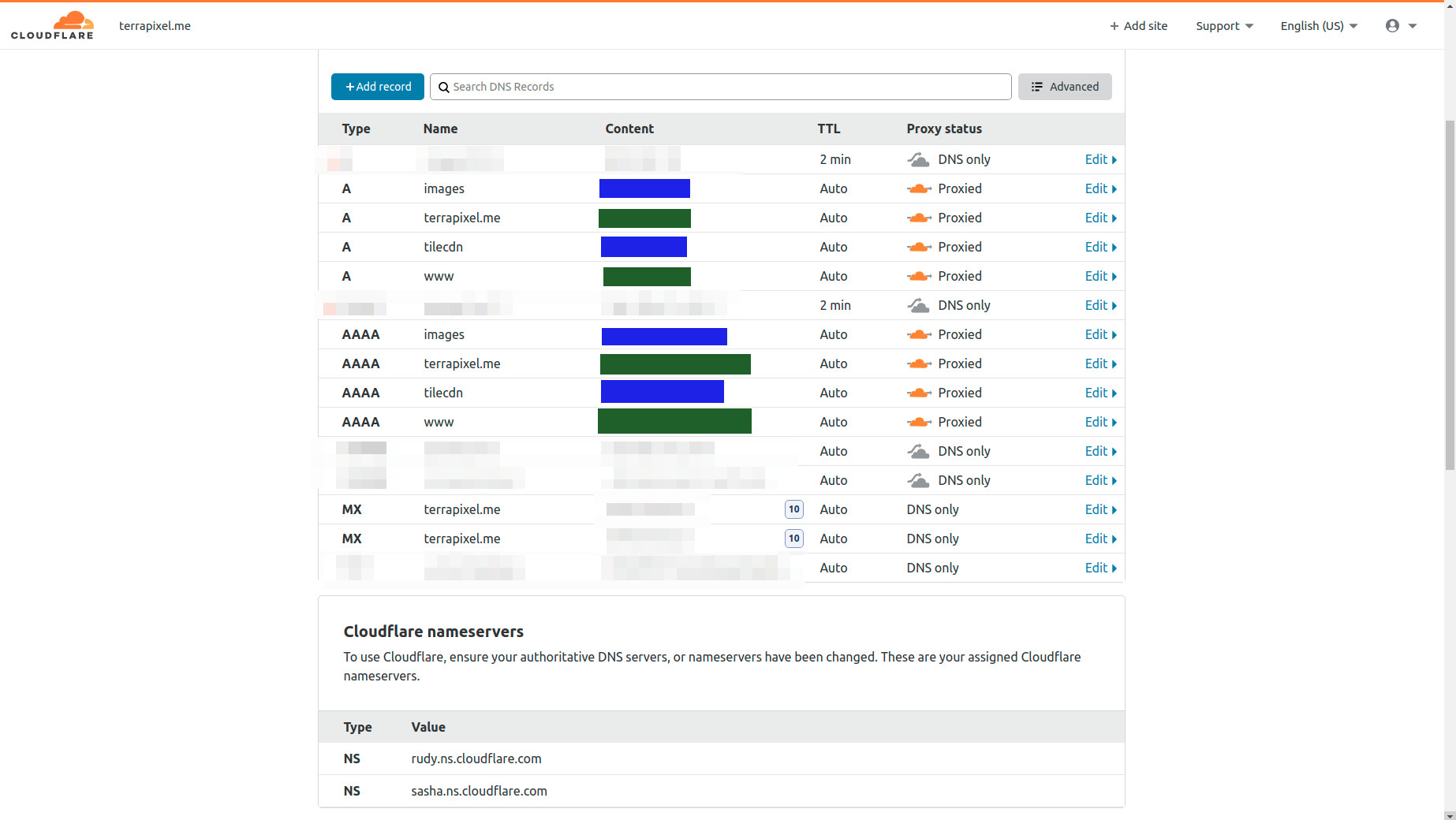
The server with this documentation is a different one than the cache server, but this is beside the point. The cache server with the reverse proxy is tilecdn and images is the webspace (on the same server) with the javascript-viewer.
For good measure you should also set up SSL. Otherwise, browsers tent to complain and it hurts your SEO ranking if you are worried about something like this.
NGINX cache
For this one you just need a small cloud server or v-server or VPS or what ever you want to call it, with at least 2 CPU cores and 2 GB RAM and the maximum amount of storage you can get.
Just fire it up with Ubuntu and install nginx
apt install nginx-full
Now just create a file /etc/nginx/sites-available/terapixel.conf and create the two virtual server configurations for the viewer:
server {
listen 80;
listen [::]:80;
access_log /var/log/nginx/images.log combined;
root /var/www/terapixel;
# Add index.php to the list if you are using PHP
index index.html index.htm index.nginx-debian.html;
server_name images.terapixel.me;
location / {
# First attempt to serve request as file, then
# as directory, then fall back to displaying a 404.
try_files $uri $uri/ =404;
}
# deny access to .htaccess files, if Apache's document root
# concurs with nginx's one
#
location ~ /\.ht {
deny all;
}
}
and the caching tile-CDN
proxy_cache_path /proxycache/local0 levels=1:2 keys_zone=terapixel:1024m inactive=120d max_size=32g use_temp_path=off;
log_format main '$remote_addr - $remote_user [$time_local] "$request" $status $body_bytes_sent "$http_referer" "$http_user_agent" "$upstream_cache_status" "$host" "$http_range" "$request_time" "$upstream_response_time"';
server {
listen 80;
listen [::]:80;
access_log /var/log/nginx/tilecdn.log main;
root /var/www/terapixel;
# Add index.php to the list if you are using PHP
index index.html index.htm index.nginx-debian.html;
server_name tilecdn.terapixel.me;
location / {
# First attempt to serve request as file, then
# as directory, then fall back to displaying a 404.
proxy_cache terapixel;
proxy_cache_key $proxy_host$request_uri;
proxy_cache_valid 200 302 10d;
proxy_cache_valid 301 1h;
proxy_cache_valid 404 1h;
proxy_cache_revalidate on;
proxy_cache_min_uses 1;
proxy_cache_background_update on;
proxy_cache_lock on;
proxy_cache_use_stale error timeout updating http_500 http_502 http_503 http_504;
proxy_ignore_headers Set-Cookie;
proxy_ignore_headers Expires;
proxy_ignore_headers Cache-Control;
proxy_set_header Host "BUCKETNAME.s3.eu-central-003.backblazeb2.com";
proxy_pass https://BUCKETNAME.s3.eu-central-003.backblazeb2.com/;
add_header X-Cache-Status $upstream_cache_status;
proxy_hide_header Cache-Control;
}
# deny access to .htaccess files, if Apache's document root
# concurs with nginx's one
#
location ~ /\.ht {
deny all;
}
}
This will cache 32 GB of tiles for up to 10 days. And even 404 are cached for an hour while generating the image we don’t hit the Backblaze backend that hard.
proxy_cache_use_stale is to still serve tiles even if the backend is down and the cache entry expired. proxy_ignore_headers and proxy_hide_header are important, because Backblaze tells proxies to not cache, which is exactly the opposite of what we want to archive.
Displaying the result
As already mentioned the image is going to be displayed as a tiled image pyramid like a Map. So we need something that can load the correct tiles for what we want to see.
And this something is “OpenSeadragon”.
An open-source, web-based viewer for high-resolution zoomable images, implemented in pure JavaScript, for desktop and mobile.
So EXACTLY what we want. For OpenSeadragon, what we have, is a “custom tile source”. Which can be used as easy as that:
<html>
<head>
<title>terapixel.me - 0072.jpg (Unus Annus)</title>
<style>
#viewer {
width: 100%;
height: 100%;
position: fixed;
top: 0;
left: 0;
}
</style>
</head>
<body>
<div id="viewer">
</div>
<script src="/openseadragon/openseadragon.min.js"></script>
<script>
osd = OpenSeadragon({
id: "viewer",
prefixUrl: "/openseadragon/images/",
navigatorSizeRatio: 0.25,
wrapHorizontal: false,
showNavigator: true,
tileSources: {
height: 1080*1080,
width: 1080*1920,
tileWidth: 1920
tileHeight: 1080,
maxLevel: 8,
minLevel: 0,
getTileUrl: function( level, x, y ){
return "https://tilecdn.terapixel.me/terapixel/0072.jpg-dump.npy/" +
level + "/" + y + "/" + x + ".jpg";
}
}
});
</script>
</body>
</html>